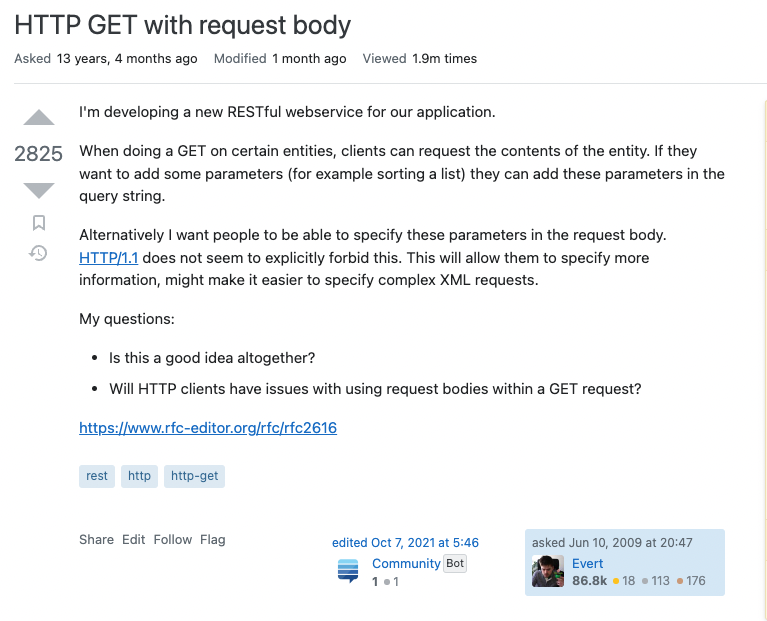
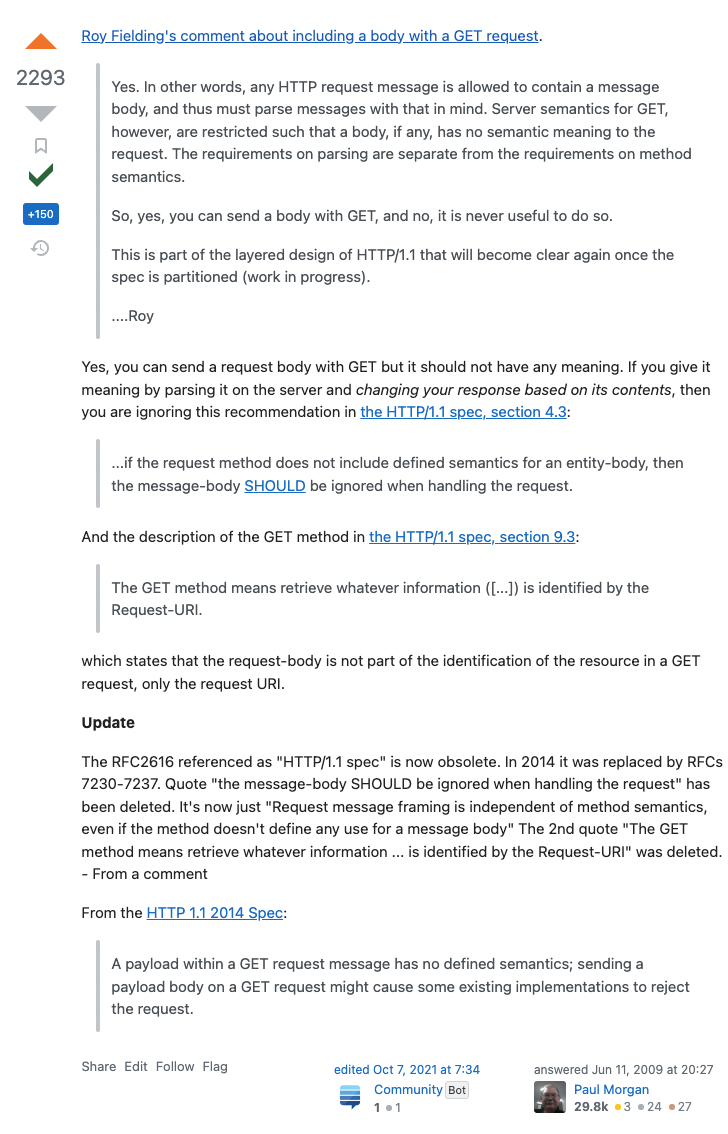
파이썬에서는 자바와 같이 Static을 남용하는 것을 지양하는 이슈가 없는 것인가 ?!
Spring으로 서버 개발을 계속해오다가 최근 Django(DRF), FastAPI로 서버개발을 하는 기회가 생기게 되었다. 새로운 프레임웤으로 개발을 하면서 낯선 부분들이 많았기에 기초적인 개념들부터 무작정 학습을 하다가, 최근 이제 View단과 Serivce단을 분리할만할 정도로 로직이 구체화되어 분리를 하던 중에 문득 이런 의문점이 들었다.
파이썬에서는 자바와 같이 static을 남용하는 것을 지양하는 이슈가 없는 것인가 ?!
레이어를 분리하면서 python에서 다른 레이어(클래스)의 메소드를 클래스 네임으로 바로 참조하여 사용하는 코드들(@classmethod, @staticmethod를 사용)을 그냥 별 생각없이 따라 사용하다가, 어라? 뭔가 찝찝하지 왜 ?(이렇게 간편하다고 ?)라는 기분이 들었다.
그리고 Spring 프레임웤에서는 어떻게 했더라 ? 생각해보니, 자바에서도 static 키워드를 사용하면 메소드와 변수를 static으로 선언할 수 있고 클래스 네임으로 바로 참조가 가능하지만 스프링에서는 그렇게 하지않는다. 그리고 객체들을 프레임웤에서 직접 관리해 주지만, 해당 객체(빈)을 등록하고 주입하기위해서는 개발자가 어느정도 객체 관리를 고려하여 어노테이션 및 코드를 짜주어야한다.
그런데 파이썬에서는 static을 남용해도 전혀 문제가 되지 않는 것인가 ?!
자바에서 static을 지양하는 이유는 다양한데, 핵심적으로는 다음과 같은 이유가 있다.
- Java에서는 static은 프로그램이 실행 시에 data영역에 생성되어서 많이 사용할 경우 메모리를 낭비하게되는 이슈가 있음.
- static이 객체지향 관점에 반하는 개념이라는 의견.
(static 사용과 관련한 많은 의견들이 있는 스택오버플로우의 한 게시글을 읽어보면 더욱 구체적으로 이유를 파악 할 수 있따.)
Django와 같은 큰 규모의 프레임워크에서 static 객체를 많이 사용한다면(@classmethod, @staticmethod), static을 남용해도 파이썬에서는 문제가 되지 않을 거라는 것을 짐작할 수는 있다. 하지만 그 이유는 무엇일까?
자바에서 static을 지양하는 대표적 이유에 근거하여 python에서는 문제가 없는 이유에 대해 몇가지 추측을 해보았다.
추측 1. @classmethod, @staticmethod를 사용해도 자바에서와 달리 파이썬에서는 data영역에 static 객체가 생성되지 않는다. ( 대신 heap영역? )
즉, 자바에서의 static 메소드처럼 @classmethod, @staticmethod을 사용하면 클래스 네임으로 접근이 가능하지만, 메모리상에서는 static이 아니다.
추측 2. 파이썬은 하이 레벨 언어로서 메모리 관리에 도가 터 있기 때문에 코드 단에서 메모리와 관련된 고려해야될 이슈가 없다.
위의 추측들을 해결하기 위해서는 Python이 어떻게 메모리를 관리하는지를 이해할 필요가 있을 것 같다.
특징 1.
우선 프로그램이 실행되면, OS는 프로세스에게 정해진 Memory를 할당해주고 프로세스는 할당받은 Memory를 자신의 방식에 맞게 영역을 나누어 활용합니다.
“메모리는 컴퓨팅 시스템에서 중요한 구조이자 프로세스의 코어한 정보들이 모여있는 공간입니다. 중요성도 높고, 휘발될 여지가 있는 만큼 대부분의 프로그래밍 언어는 내장된 memory manager를 구성하여 둡니다. Python의 경우 VMM이 할당해준 빈 페이지들은 Python의 memory manager가 권한을 가지고 있습니다.
Python은 기본적으로 할당된 Memory 공간을 4개의 종류로 구분하여 관리합니다.
HEAP / STACK / Static&Global / CODE
HEAP, STACK 이 두가지 영역은 Dynamic memory allocation 과 static memory allocation을 위해 존재합니다. 이 두 영역의 메모리 할당 방식과 작동 원리는 Generator와 함께 이해하는 것이 좋습니다. 이를 위해 다음 글에서 자세히 다뤄보겠습니다.
Static&Global 영역은 전역 변수 등을 다루기 위해 할당되는 공간입니다. Code 영역은 instruction 들이 보관되는 영역입니다. 프로세스가 각 명령줄을 보관하는 목적으로 사용하는 공간입니다.
Python과 관련하여 메모리 관련 이해도가 필요한 부분은 heap 과 stack 부분인데, 이 부분에 대한 이해도가 높을 수록 성능과 효율성을 고려한 코드가 나오는 것 같습니다.” [원문 - https://day-by-day.kr/python-memory/]
위의 글에서 파이썬은 heap 영역과 stack영역을 핵심적으로 사용하며 static memory allocation (정적 메소드 생성과 같은)도 heap, stack영역을 사용하는 것을 알 수 있다.
특징 2.
또한 파이썬은 모든 것이 ‘객체'로 저장된다. 예를 들어 c언어에서는 x=10이라고 변수를 할당하면 메모리에 해당 값이 바로 저장되지만, 파이썬에서는 int라는 object를 만들어 변수 x가 해당 객체(10이 담겨있는 int 객체)를 가리키는 형태로 저장된다고 한다.
특징 3.
파이썬은 개발자가 직접 동적 할당을 할 수 있는 기능이없다.(ex c의 malloc) 파이썬은 자동으로 메로리를 관리해주는 언어이기 때문. python memory manager는 자동으로 포인터를 움직여서 메모리 할당범위를 조절해주며, 동적 관리를 한다. 또한 운영체제와 소통하면서 manager가 알아서 메모리를 관리함으로써 OS의 부담을 줄여주는 언어다.
참고자료 - https://woochan-autobiography.tistory.com/867
결론적으로 파이썬은 정적 메소드에 대해 data영역을 사용하지 않으며 메모리 관리에 우수한 성능을 가지고 있기 때문에 메모리와 관련하여 코드단에서 고려해야될 요소가 없다고 판단함.
다만 정확히 @staticmethod, @classmethod데코레이터를 붙인 클래스의 메소드가 어떻게 메모리에 할당되는 지에 대해 알면 더욱 정확한 결론을 얻을 수 있을 것이라 생각한다. 이를 위해서는 python memory manager에 대한 공부가 필요함!
파이썬 memory management에 관한 공식 문서